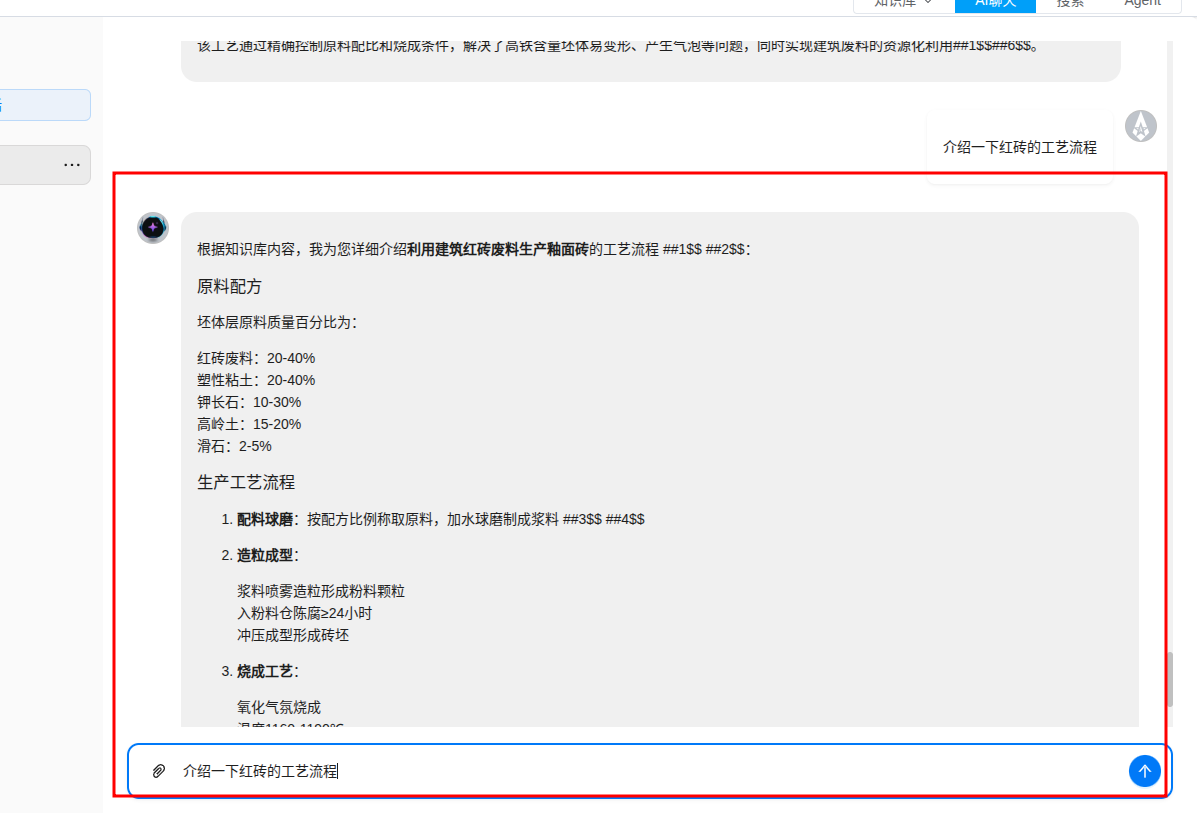
工业智能助理¶
知识库、无幻觉聊天和文件管理是RAGFlow的三大支柱。星观网络 中的聊天内容基于某个特定数据集或多个数据集。run a retrieval test创建完数据集、完成文件解析并运行检索测试后,你就可以继续展开人工智能对话了。
开始一个AI聊天¶
创建一个AI助理¶
点击按钮创建一个AI助理
配置¶
| 表单名 | 类型 | 描述 |
|---|---|---|
| 助理设置-助理姓名 | 字符串 | 助理姓名 |
| 助理设置-助理描述 | 字符串 | 助理描述 |
| 助理设置-助理头像 | 字符串 | 助理头像,图片存储url地址 |
| 助理设置-空回复 | 字符串 | 如果在知识库中没有检索到用户的问题,它将使用它作为答案。 如果您希望 LLM 在未检索到任何内容时提出自己的意见,请将此留空。 |
| 助理设置-设置开场白 | 字符串 | 您想如何欢迎您的客户? |
| 助理设置-显示引文 | 开关 | 是否应该显示原文出处? |
| 助理设置-文本转语音 | 开关 | 是否用语音转换播放语音,请先在设置里面选择TTS(语音转换模型)。 |
| 助理设置-知识库 | 选择数据 | 选择关联的知识库。 |
| 提示引擎-系统提示词 | 字符串 | 当LLM回答问题时,你需要LLM遵循的说明,比如角色设计、答案长度和答案语言等。 |
| 提示引擎-相似度阈值 | 数值 | 我们使用混合相似度得分来评估两行文本之间的距离。 它是加权关键词相似度和向量余弦相似度。 如果查询和块之间的相似度小于此阈值,则该块将被过滤掉。默认设置为 0.2,也就是说文本块的混合相似度得分至少 20 才会被召回。 |
| 提示引擎-关键字相似度权重 | 数值 | 我们使用混合相似性评分来评估两行文本之间的距离。它是加权关键字相似性和矢量余弦相似性或rerank得分(0〜1)。两个权重的总和为1.0。 |
| 提示引擎-Top N | 数值 | 并非所有相似度得分高于“相似度阈值”的块都会被提供给大语言模型。 LLM 只能看到这些“Top N”块。 |
| 提示引擎-变量 | 选择数据 | 你可以通过对话 API,并配合变量设置来动态调整大模型的系统提示词。 {knowledge}为系统预留变量,代表从指定知识库召回的文本块。 “系统提示词”中的所有变量都必须用大括号{}括起来。详见 https://ragflow.io/docs/dev/set_chat_variables。 |
| 模型设置-温度 | 数值 | 该参数控制模型预测的随机性。 较低的温度使模型对其响应更有信心,而较高的温度则使其更具创造性和多样性。 |
| 模型设置-topP | 数值 | 该参数也称为“核心采样”,它设置一个阈值来选择较小的单词集进行采样。 它专注于最可能的单词,剔除不太可能的单词。 |
| 模型设置-存在处罚 | 数值 | 这会通过惩罚对话中已经出现的单词来阻止模型重复相同的信息。 |
| 模型设置-频率惩罚 | 数值 | 与存在惩罚类似,这减少了模型频繁重复相同单词的倾向。 |
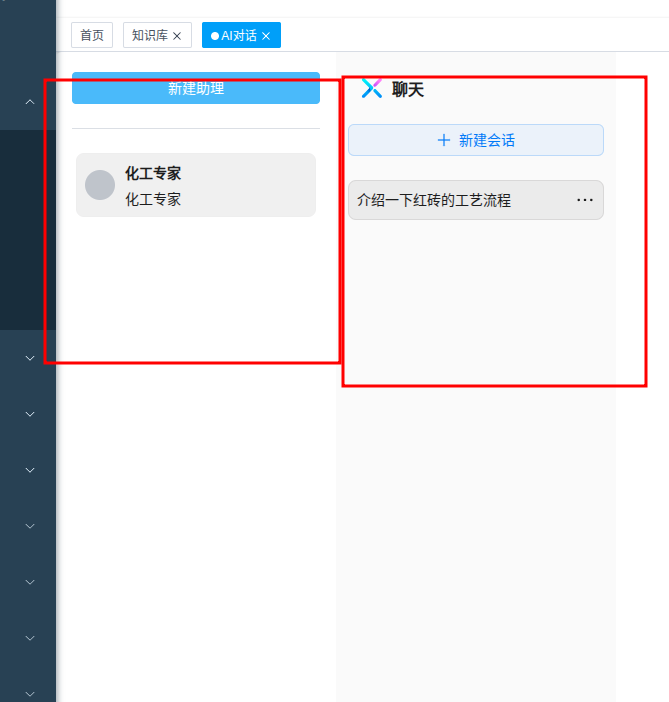
发起会话¶
选择聊天助手,选择一个会话框
发起聊天¶
对话框中输入问题,获取智能体对问题的解答
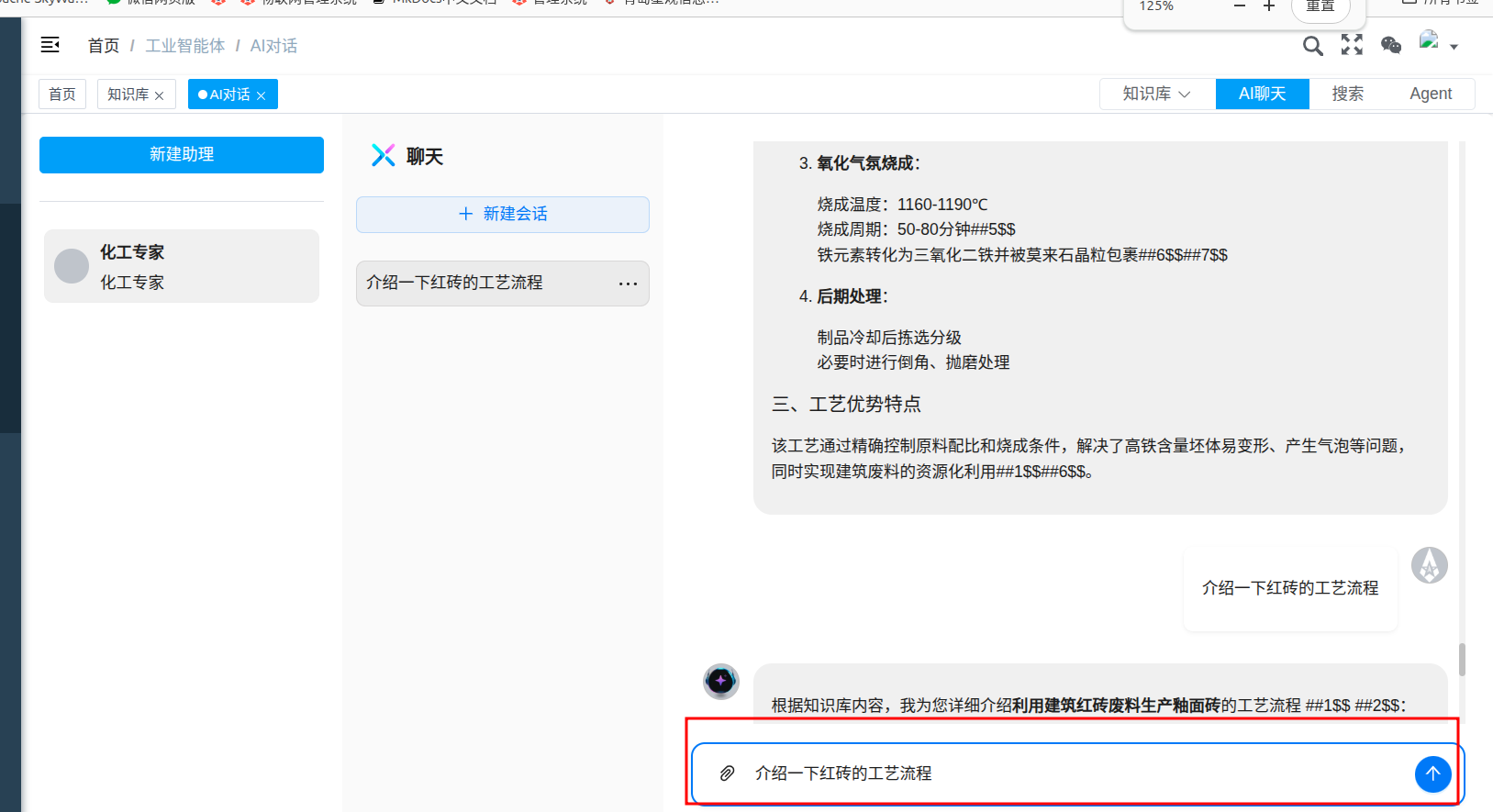
智能体做出回答